
精准狙击Llama 3.1?Mistral AI开源Large 2,123B媲美Llama 405B
精准狙击Llama 3.1?Mistral AI开源Large 2,123B媲美Llama 405BAI 竞赛正以前所未有的速度加速,继 Meta 昨天推出其新的开源 Llama 3.1 模型之后,法国 AI 初创公司 Mistral AI 也加入了竞争。
来自主题: AI技术研报
10382 点击 2024-07-25 18:32
 搜索
搜索
AI 竞赛正以前所未有的速度加速,继 Meta 昨天推出其新的开源 Llama 3.1 模型之后,法国 AI 初创公司 Mistral AI 也加入了竞争。

就在刚刚,Meta 如期发布了 Llama 3.1 模型。

导读:时隔4个月上新的Gemma 2模型在LMSYS Chatbot Arena的排行上,以27B的参数击败了许多更大规模的模型,甚至超过了70B的Llama-3-Instruct,成为开源模型的性能第一!
众所周知,对于 Llama3、GPT-4 或 Mixtral 等高性能大语言模型来说,构建高质量的网络规模数据集是非常重要的。然而,即使是最先进的开源 LLM 的预训练数据集也不公开,人们对其创建过程知之甚少。

深度学习领域知名研究者、Lightning AI 的首席人工智能教育者 Sebastian Raschka 对 AI 大模型有着深刻的洞察,也会经常把一些观察的结果写成博客。在一篇 5 月中发布的博客中,他盘点分析了 4 月份发布的四个主要新模型:Mixtral、Meta AI 的 Llama 3、微软的 Phi-3 和苹果的 OpenELM。

我们知道,Meta 推出的 Llama 3、Mistral AI 推出的 Mistral 和 Mixtral 模型以及 AI21 实验室推出的 Jamba 等开源大语言模型已经成为 OpenAI 的竞争对手。

随着 Llama 3 发布,未来大模型的参数量已飙升至惊人的 4000 亿。尽管每周几乎都有一个声称性能超强的大模型出来炸场,但 AI 应用还在等待属于它们的「ChatGPT 时刻」。其中,AI 智能体无疑是最被看好的赛道。
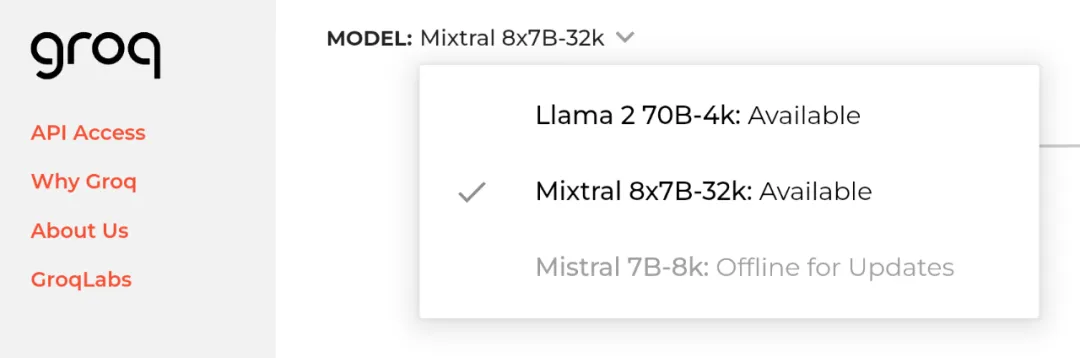
2024 年 4 月 20 日,即 Meta 开源 Llama 3 的隔天,初创公司 Groq 宣布其 LPU 推理引擎已部署 Llama 3 的 8B 和 70B 版本,每秒可输出token输提升至800。

开源最近成了 AI 圈绕不开的高频热门词汇。 先有 Mistral 8x22B 闷声干大事,后有 Meta Llama 3 模型深夜炸场,现在连苹果也要下场参加这场激烈的开源争霸赛。
最近,Meta 推出了 Llama 3,为开源大模型树立了新的标杆。